How K8s Scheduler Works
Aug 3 2021Kubernetes is the mostly wide used Container ecosystem in present times. With it’s roots dating back to Google’s Borg, Kubernetes is itself a collection of multiple microservices. The Kubernetes architecture comprises of around 5 major components in it’s master plane. And kube-apiserver being the heart of whole cluster, there is one component called kube-scheduler which is actually responsible for managing the workloads throughout the cluster. Though there is not much available in detail regarding kube-scheduler’s working in Kubernetes docs, with this blog post I’ll try to bring some less explored and mysterious ways kube-scheduler works.
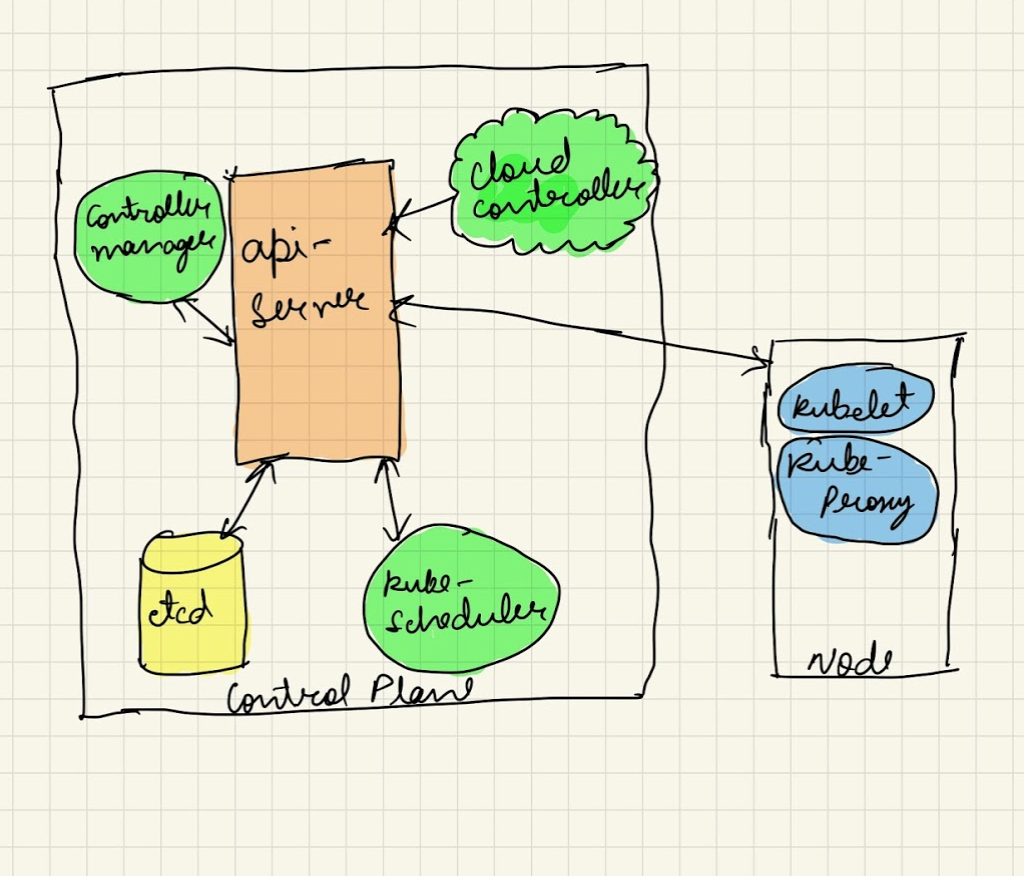
kube-scheduler is the default scheduler for Kubernetes which resides in the master (or control) plane. Being a default scheduler does not imply it’s the only scheduler, but we can also use our own custom scheduler if required. The scheduler’s main function is to assign newely created pod in the cluster to a feasible worker node as per the optimal resource requirements of the containers inside the pod. If scheduler isn’t able to find a feasible node for the pod, the pod remains unscheduled in the cluster.
To understand this, let me first roll-my sleeves on a Pod’s lifecycle.
When we issue a command to create a new deployment or a single pod,
the newely created pod does not get immediately assigned to a worker
node. The kubectl interacts with kube-apiserver only, in-fact every
other component of master plane also does the same. When the call is
issued to create a new deployment, the deployment controller(inside
kube-controller manager) notices with the help of deployment informer
that there is a new deployment created and creates a replicaset in
it’s logic. The replicaset controller notices the new replicaset and
creates a pod object. This is very important to remember that the pod
is not created by the deployment controller directly but instead by
the replicaset controller. Now, the scheduler inside the
kube-scheduler (also a controller) notices a new pod with an empty
spec.NodeName field and puts it into the scheduling queue. And at
the same time, the kubelet which is also a type of controller
notices the new pod (via the pod informer). But since the pod still
has an empty spec.NodeName field and which doesn’t matches the
kubelet’s node name. So the kubelet ignores the pod and goes to sleep
for the time being. The kube-scheduler then takes the pod out of it’s
queue and puts it onto a node with enough resources. I’ll explain the
criteria involved in selecting a node by scheduler for a pod, but
meanwhile once scheduled the spec.NodeName of the pod is also
updated with the correct node name. Right after that, the Kubelet
recognizes the pod because of a pod update event, compares the pod’s
spec.NodeName to it’s node name. And if the name matches, the
kubelet starts the containers of the pod and reports back to
api-server that the containers have been started by updating the Pod
status.
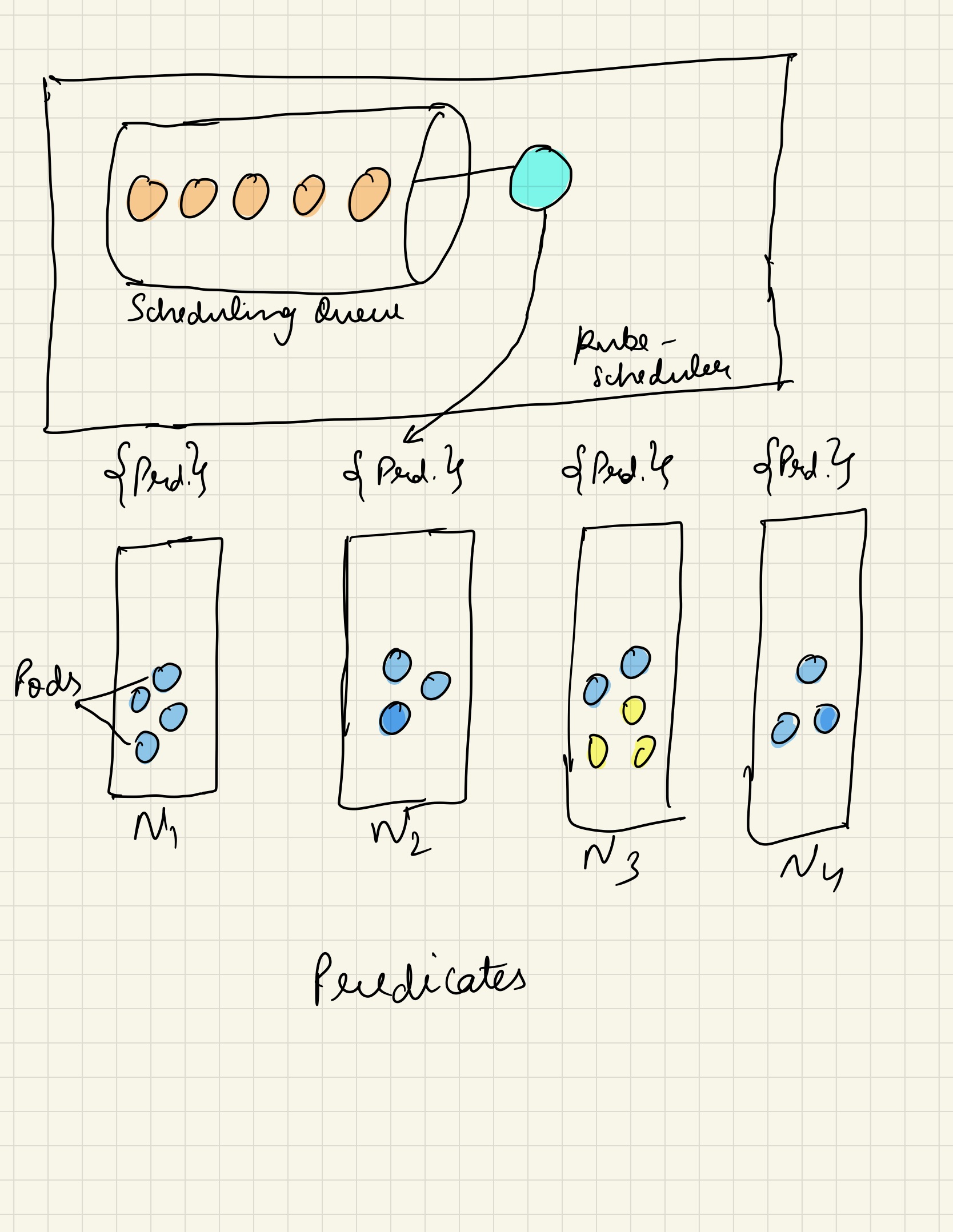
There are two important factors responsible for the scheduling of a pod onto a node, Predicates or Filters & Priorities or Soft Constraints. Predicates, are hard constraints something like - I want my pod to have 1GB of memory and 1 core of CPU and it should exist with a pod of different kind, tolerate some taints. The scheduler has a scheduling-queue which watches on the kube-apiserver for the pods that are yet to be assigned to a particular node. When a pod is moved out of the scheduling queue, the pod predicates are applied parallely on all the available nodes followed by series of checks to run. The node that satisfies all the requirements gets the pod. Priorities, also known as soft constraints follow score based scheduling process. For each priority, each selected node gets a score and the sum of the score helps in the final scheduling of the pod at the end. When the pod is moved out of a scheduling queue, the priorties are applied to all the available nodes, score is calculated and the node with highest score gets the pod assigned to it. Below are few key-features of kube-scheduler
- Handling resource requests on containers like CPU, Memory, Storage, HostPath
- Taints & Tolerations
- NodeSelector, NodeAffinity
- PodAffinity, PodAntiAffinity
- PodTopologySpread
- Priority, pre-emption
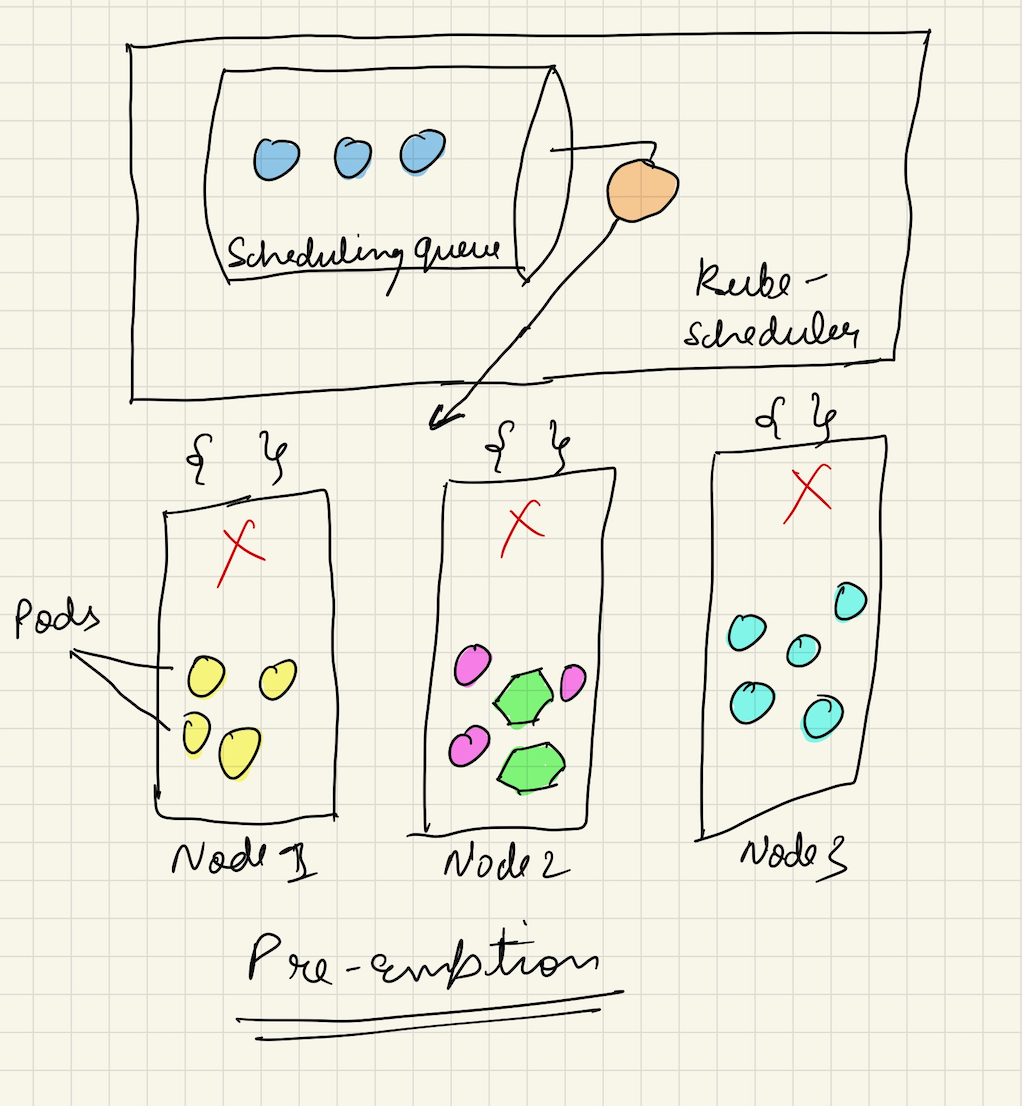
There is one more phenomenon called as Preemption which comes into effect when all the nodes aren’t fit for a pod to be scheduled over. The pre-emption happens on all the nodes simultaneously and to fit a new pod in this scenario, the pod with lowest priority is killed onto a node.
A pod priority can be configured as below,
apiVersion: v1
kind: Pod
metadata:
name: test-pod
labels:
env: dev
spec:
containers:
- name: ash-container
image: alpine:latest
imagePullPolicy: IfNotPresent
priorityClassName: high-priority
And the PriorityClass looks like,
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: "This priority class is a high priority class"
And a preempting priority class would look like,
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority-one-up
value: 1000000
preemptionPolicy: Never
globalDefault: false
description: "This priority class will not evict other pods"
More information on preemption is available here.
Let’s take a look at how a scheduler is configured. You can configure a custom scheduler profile by using the command, kube-scheduler - -config , where filename represents a custom configuration file which can look like,
apiVersion: kubescheduler.config.k8s.io/v1beta1
kind: KubeSchedulerConfiguration
clientConnection:
kubeconfig: /etc/srv/kubernetes/kube-scheduler/kubeconfig
One very important component which I’ve mentioned multiple times earlier in this post is, Scheduling Queue. The Scheduling Queue in kube-scheduler allows scheduler to pick the pod for next scheduling cycle. This mechanism is based on three main queues:
- Active Queue, which provides pods for immediate scheduling
- Unschedulable Queue, this is for parking pods that are waiting for certain condition to occur
- PodBackOff Queue, this queue is for exponentially postponing pods which are failed to scheduled but are expected to get scheduled eventually (ex. persistent volumes are still getting created)
The scheduling queue has two active flushing mechanisms running in the background responsible for moving pods in the ActiveQ,
- flushUnschedulableQLeftOver: runs every 30 seconds and moves pods from unschedulable queue to allow unschedulable pods that were left without any wakeup condition.
- flushBackOffQCompleted: running every second and moves pods that were backed-off long enough to the active queue.
Scheduling Queue is actually a very big topic in itself, I’ll try to include some more points in other post.
The kube-scheduler’s code is available here if you want to explore more. More details w.r.t Kubernetes’s sig/scheduling can be found here. kube-scheduler is the brain of Kubernetes container ecosystem and a very interesting topic in itself. In my next post, I’ll try to cover few more relative topics and other projects associated with kube-scheduler. Until then, ciao!